I try to undeploy a VM in sunstone. It fails with the following error (from the log):
Tue May 29 11:54:25 2018 [Z0][VM][I]: New LCM state is EPILOG_UNDEPLOY
Tue May 29 11:54:32 2018 [Z0][TM][I]: Command execution fail: /var/lib/one/remotes/tm/ssh/mv localhost:/var/lib/one//datastores/0/5 server.anonymous.nowhere:/var/lib/one//datastores/0/5 5 0
Tue May 29 11:54:32 2018 [Z0][TM][I]: mv: Moving localhost:/var/lib/one/datastores/0/5 to server.anonymous.nowhere:/var/lib/one/datastores/0/5
Tue May 29 11:54:32 2018 [Z0][TM][E]: mv: Command “set -e -o pipefail
Tue May 29 11:54:32 2018 [Z0][TM][I]:
Tue May 29 11:54:32 2018 [Z0][TM][I]: tar -C /var/lib/one/datastores/0 --sparse -cf - 5 | ssh server.anonymous.nowhere ‘tar -C /var/lib/one/datastores/0 --sparse -xf -’
Tue May 29 11:54:32 2018 [Z0][TM][I]: rm -rf /var/lib/one/datastores/0/5” failed: tar: 5: Cannot stat: No such file or directory
Tue May 29 11:54:32 2018 [Z0][TM][I]: tar: Exiting with failure status due to previous errors
Tue May 29 11:54:32 2018 [Z0][TM][E]: Error copying disk directory to target host
Tue May 29 11:54:32 2018 [Z0][TM][I]: ExitCode: 2
Tue May 29 11:54:32 2018 [Z0][TM][E]: Error executing image transfer script: Error copying disk directory to target host
Tue May 29 11:54:32 2018 [Z0][VM][I]: New LCM state is EPILOG_UNDEPLOY_FAILURE
After that the Image corresponding to the VM is in state ERROR.
I use OpenNebula 5.4.0 and libvirt 3.9.0 on CentOS 7.
Could this be related to my mountpoints in datastore?
from my fstab:
/dev/opennebula_datastore_1/vm_images /var/lib/one/datastores/1 xfs defaults 0 0
/dev/data/opennebula_datastore_0 /var/lib/one/datastores/0 xfs defaults 0 0
My solution is to simply not use the feature undeploy. I just delete VMs. I was not able to fix it. It seems like the undeploy script is trying to move a file which is already deleted during undeploy process.
I have not changed any settings at the datastore, these are the default settings that were present after the installation.
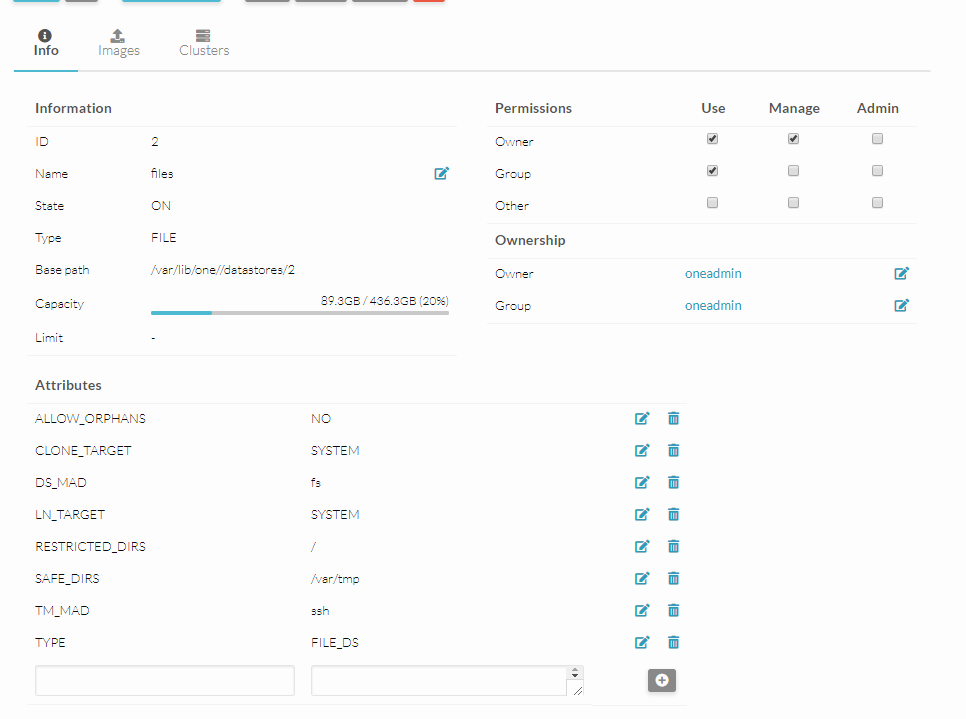
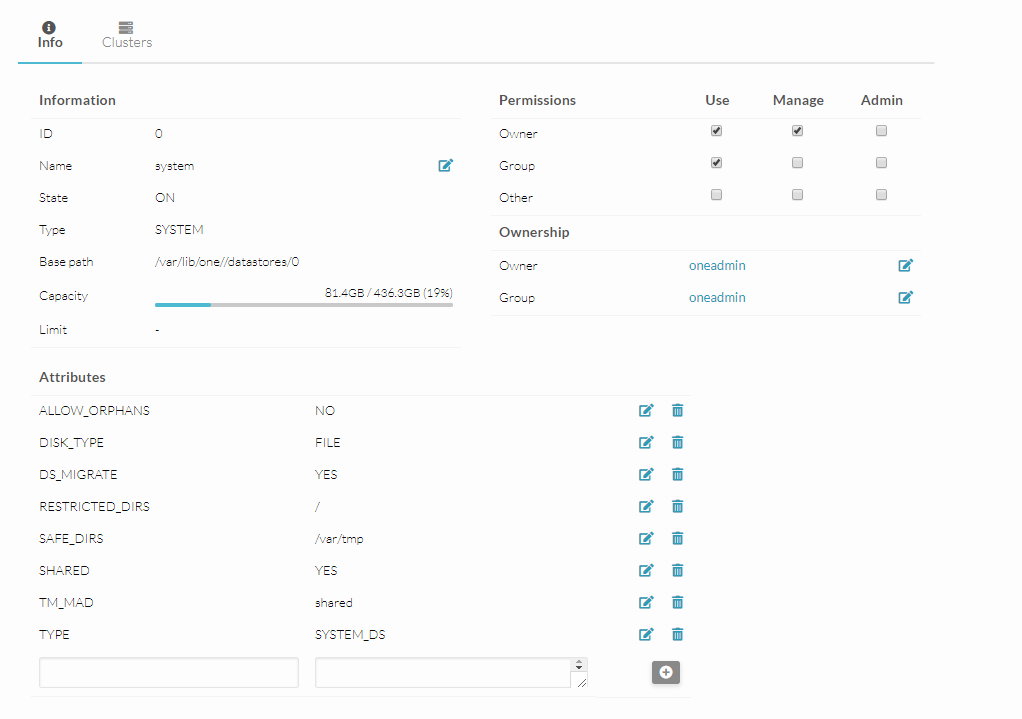
Sorry, but what do you mean with “TM_MAD”?
The ssh driver deletes the destination path before copying the VM disk image files back to the front-end during Undeploy. So if the system datastore is on a shared filesystem you’ll have behavior like the explained. Also if the source and the destination is same machine but with different names you’ll have same situation - same filesystem for both source and destination…
Thank you very much for your answer!
So I have to change TM_MAD to “shared”, right?
And do I have to change it on the files and default datastore, or only one of them?
There are two options then:
a) fix the hostnames so the source and the destination paths will be same. Then the ssh driver will detect that it is dealing with same host and do nothing.
b) try changing the TM_MAD for both SYSTEM and IMAGE datastores to “shared”
Thank you.
Unfortunately changing TM_MAD to shared didn’t help.
But I would be very happy if you could explain in more detail what you mean by option a.
Did you try instantiatiing a new VM and then undeploy it?
Here is the relevant log from the other thread:
Sat Jul 21 11:00:58 2018 [Z0][TM][I]: Command execution failed (exit code: 2): /var/lib/one/remotes/tm/ssh/mv localhost:/var/lib/one//datastores/0/51 virt.xxxx.de:/var/lib/one//datastores/0/51 51 0
Sat Jul 21 11:00:58 2018 [Z0][TM][I]: mv: Moving localhost:/var/lib/one/datastores/0/51 to virt.xxxxx.de:/var/lib/one/datastores/0/51
Here the tm/ssh/mv script is ordered to move VM’s home folder from hypervisor named localhost to front-end named virt.xxxxx.de. If it is a single host both source and destination should be with same host:path and tm/ssh/mv will hit the following condition: https://github.com/OpenNebula/one/blob/master/src/tm_mad/ssh/mv#L62
That will skip the entire directory move because it is same host.
I just deployed a new VM and now it seems to work!
But I’ll also have a look at the SSH problem you mentioned.
I have to figure out where he takes the hostname from, when I added the host I have set “localhost” as the hostname.
You are still having same issue - trying to move files on same host where the mv script can’t recognize that it is same host and is deleting files instead of bailing out.